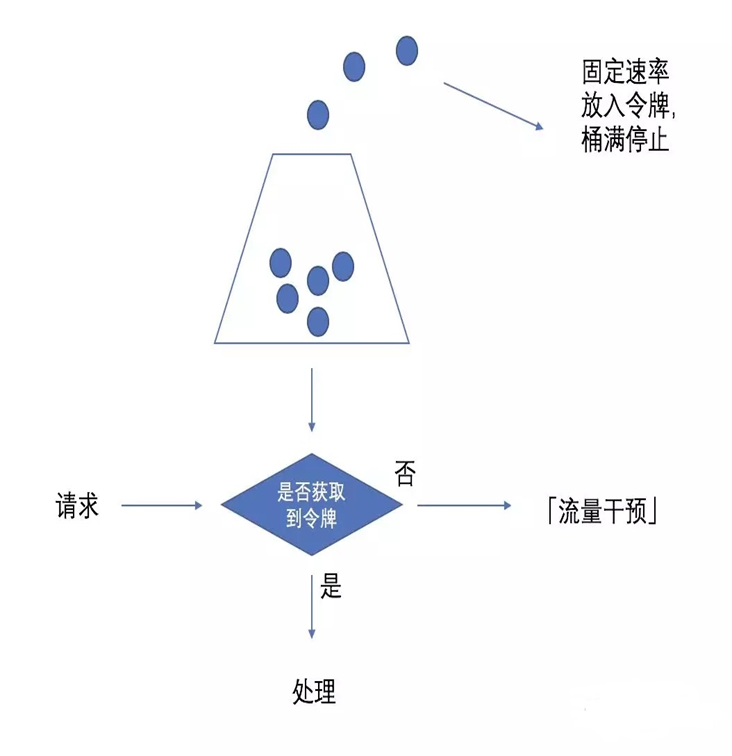
.
.
.
.
.
.
.
.
.纯干货
.
.
.
.
.
.
目录
前馈神经网络
基本原理
公式解释
一个示例
卷积神经网络
基本原理
公式解释
一个示例
循环神经网络
基本原理
公式解释
一个案例
长短时记忆网络
基本原理
公式解释
一个示例
自注意力模型
基本原理
自注意力机制
具体步骤
公式解释
一个案例
生成对抗网络
基本原理
公式解释
一个案例
最后
人工神经网络(Artificial Neural Network,ANN)是一种受到生物神经系统启发的计算模型,用于模拟和处理复杂的信息处理任务。
人工神经网络由许多神经元(或称为节点)组成,这些神经元通过连接(也称为权重)相互连接,形成了一个网络结构,以模拟大脑中神经细胞之间的相互作用。
下面,咱们大概介绍一下关于 ANN 的组成部分和工作原理:
1、神经元(Neurons):神经元是神经网络的基本单元,它们接收输入、执行计算并生成输出。每个神经元都有一个激活函数,用于将输入信号转换为输出信号。典型的激活函数包括Sigmoid、ReLU(Rectified Linear Unit)和Tanh(双曲正切)等。
2、层(Layers):神经网络通常由多个层组成,包括输入层、隐藏层和输出层。输入层用于接收原始数据,隐藏层用于提取特征,输出层用于生成最终的预测或结果。
3、连接权重(Connection Weights):每个神经元之间的连接都有一个权重,它表示了不同神经元之间信息传递的强度。这些权重是通过训练过程中自动学习得到的,以使神经网络能够适应特定任务。
4、前向传播(Feedforward):在前向传播中,输入信号从输入层传递到输出层,通过神经元之间的连接传递,并最终产生预测或输出。前向传播过程是通过计算每个神经元的加权和并应用激活函数来完成的。
5、训练(Training):神经网络的训练过程是通过反向传播算法来完成的。训练期间,网络与标记数据进行比较,计算预测与实际值之间的误差,并通过调整连接权重来减小误差。这个过程通过梯度下降算法来实现,以最小化损失函数。
6、损失函数(Loss Function):损失函数用于度量模型的预测与实际值之间的差距。训练的目标是最小化损失函数的值。
7、激活函数(Activation Function):激活函数在神经元内部计算输入的加权和后,将结果转换为神经元的输出。它们引入非线性性,允许神经网络捕捉更复杂的模式。
8、反向传播(Backpropagation):反向传播是一种迭代的优化过程,用于根据损失函数的梯度调整连接权重,以改进神经网络的性能。这个过程从输出层向后传递误差信号,并根据误差信号来更新权重。
9、深度神经网络(Deep Neural Networks):包含多个隐藏层的神经网络被称为深度神经网络。它们在处理复杂问题和大规模数据集时表现出色,例如图像识别、自然语言处理和语音识别。
10、应用领域:人工神经网络用于机器学习和人工智能的几乎每个领域,包括图像识别、语音识别、自然语言处理、推荐系统、自动驾驶、金融预测等等。
接下来,从下面 6 部分详细说说关于ANN 的内容:
-
前馈神经网络
-
卷积神经网络
-
循环神经网络
-
长短时记忆网络
-
自注意力模型
-
生成对抗网络
一起来看看~
前馈神经网络
前馈神经网络灵感来自于人脑的神经元。它的工作方式如同信息在不同层之间前馈传递,就像传送带一样。
这种传递是单向的,不会形成回路,因此称为“前馈”。
基本原理
前馈神经网络由多个神经元组成,这些神经元排列成不同的层次:输入层、隐藏层和输出层。
-
输入层:接受你提供的数据,例如图像的像素值或文本的单词。
-
隐藏层:网络的核心,负责处理输入数据。它可以有多层,每一层都执行一些数学运算。
-
输出层:输出层给出了最终的结果,如图像中的对象类型或文本的情感。
一个示例
考虑以下的问题:我们有一组学生的考试成绩(数学和语文),我们想根据这些成绩来预测学生是否会被大学录取。
首先,我们创建一个前馈神经网络模型。
案例中使用 TensorFlow 进行实现:
import tensorflow as tf
from tensorflow.keras import layers, models
import matplotlib.pyplot as plt
# 创建示例数据集
data = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = data.load_data()
# 构建前馈神经网络
model = models.Sequential([
layers.Flatten(input_shape=(28, 28)),
layers.Dense(128, activation='relu'),
layers.Dense(10, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 训练模型
history = model.fit(train_images, train_labels, epochs=10, validation_data=(test_images, test_labels))
# 绘制训练损失曲线
plt.plot(history.history['loss'], label='训练损失')
plt.plot(history.history['val_loss'], label='验证损失')
plt.xlabel('Einpochs')
plt.ylabel('损失')
plt.legend()
plt.show()代码中使用了TensorFlow和Fashion MNIST数据集来创建一个前馈神经网络模型。
前馈神经网络是深度学习的基础,模拟了大脑中神经元的工作方式。通过学习权重和偏差,这些网络可以适应各种任务。
卷积神经网络
想象一下,你要辨认一张图片中的狗,你会先注意到图像的一些局部特征,如眼睛、鼻子、耳朵等,然后将这些特征组合在一起,最终确定这是一只狗。CNN就像模拟这个过程的机器。
CNN通过层层的计算,从图像中提取特征,然后将这些特征组合在一起来进行图像分类。这个过程就像你在拼图中找到每个小块的形状和颜色,最后把它们组合成完整的图像。
基本原理
卷积神经网络的核心思想是卷积操作。卷积是一种数学运算,它通过在输入图像上滑动一个小窗口(通常称为卷积核或滤波器)来检测图像中的特征。
这个卷积核会在图像上不断平移,每次计算一个局部区域的加权和,从而生成一个特征图。这个特征图的每个元素代表着检测到的特征的强度。
卷积操作具有局部性质,这意味着它只关注图像的一小部分,这与我们人类观察图像的方式相似。这也使得CNN对平移、旋转和缩放具有一定的不变性,因为它们可以检测到相同的特征,无论这些特征在图像中的位置如何变化。
一个示例
为了更好地理解,让我们考虑一个经典的图像分类问题:手写数字识别。
我们使用Python和TensorFlow来构建一个CNN模型,并将其应用于MNIST数据集,该数据集包含手写数字图像。
import tensorflow as tf
from tensorflow.keras import layers, models
import matplotlib.pyplot as plt
# 载入MNIST数据集
mnist = tf.keras.datasets.mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# 创建卷积神经网络模型
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
history = model.fit(train_images, train_labels, epochs=5,
validation_data=(test_images, test_labels))
# 可视化训练过程
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label='val_accuracy')
plt.xlabel('Epochs')
plt.ylabel('accuracy')
plt.legend()
plt.show()代码中演示了如何构建一个CNN模型,用于手写数字识别,以及如何训练该模型。
可以看到,准确率逐渐提高,这是因为CNN学会了从图像中提取特征。
卷积神经网络通过卷积操作来提取图像中的特征,从而实现图像分类等任务。
当然上述例子只是浅尝辄止,大家可以根据自己的实际情况进一步深入学习。
循环神经网络
循环神经网络(RNN)就像一个有记忆的模型,它可以处理序列数据,如文本、音频、时间序列等。通过不断地传递信息并保持内部状态,从而能够理解数据的上下文。
举个例子,假设你在阅读一本小说。你需要记住前几页的情节,因为它们可能会影响后面的故事发展。RNN就是模拟这种记忆的过程。
基本原理
RNN的基本构建块是神经元,它接受输入和内部状态,并输出。这个内部状态是网络的记忆,用来存储之前看到的信息。
RNN中有一个循环连接,它允许信息在不同时间步之间传递。这个循环连接就像书中的页码,你可以从前一页跳到下一页。这允许RNN处理任意长度的序列数据。
一个案例
为了更好地理解RNN,咱们考虑用一个时间序列数据的简单问题。
使用Python和TensorFlow来构建一个RNN模型,并将其应用于天气预测。
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 创建示例时间序列数据
time_steps = np.linspace(0, 100, num=100)
sin_wave = np.sin(time_steps)
# 准备数据
X, y = [], []
for i in range(len(sin_wave) - 10):
X.append(sin_wave[i:i+10])
y.append(sin_wave[i+10])
X = np.array(X)
y = np.array(y)
# 构建RNN模型
model = tf.keras.Sequential([
tf.keras.layers.SimpleRNN(10, input_shape=(10, 1)),
tf.keras.layers.Dense(1)
])
# 编译模型
model.compile(optimizer='adam', loss='mean_squared_error')
# 训练模型
model.fit(X, y, epochs=100, batch_size=16)
# 预测结果
predicted = model.predict(X)
# 可视化结果
plt.plot(time_steps[10:], y, label="accuracy_data")
plt.plot(time_steps[10:], predicted, label="predict_data")
plt.legend()
plt.show()模型在经过训练后能够较好地拟合实际数据,从而进行预测。